HTML網頁的標題文字是使用<hn>標籤來定義標題文字,從<h1>到<h6>有六種不同尺寸的標題文字,<h1>最重要,依序遞減至<h6>,而h旁邊的數字愈大則代表著字型尺寸愈小。
現在,我們就來使用Web Scraper爬取<h1><h2><h3>前三個標題文字標籤。
本次練習網址為:https://fchart.github.io/test/ex2_01.html
進入瀏覽器後,請在瀏覽器按F12或是Ctrl+Shfit+I開啟開發人員工具,停駐視窗選擇在下方,如下圖:
選擇元素(Elements)標籤,如下圖:
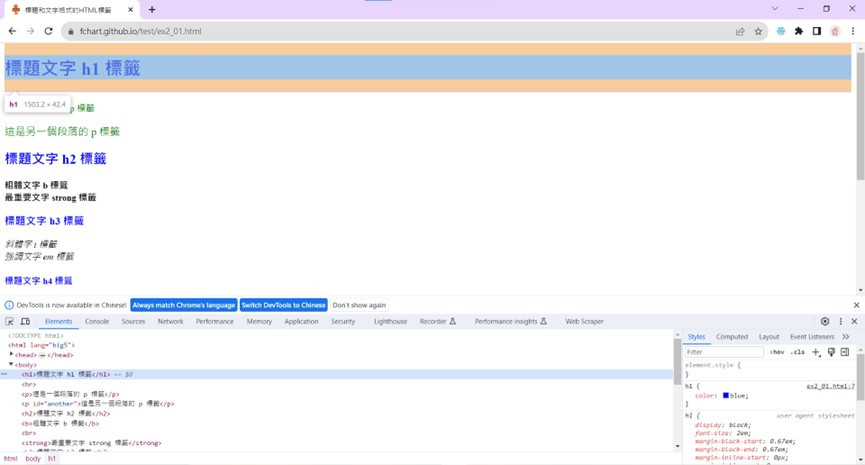
在<body>下可以依序看到<h1>~<h6>標籤,這些就是欲爬取目標資料所在的HTML標籤。
1.切換至開發人員工具後,點選Web Scraper標籤開啟Web Scraper,執行Create new sitemap → Create Sitemap命令新增網站地圖。
2.在Sitemap name輸入名稱,需使用小寫英文字母和底線,
在Strat URL欄輸入起始URL網址後按Create Sitemap紐新增網站地圖。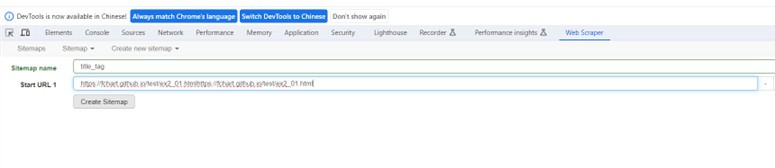
成功建立地圖專案後,就可開始新增CSS選擇器。
1.在下方Add new Selector紐新增目前 _root節點下的CSS選擇器節點。
2.進入後在Id欄輸入名稱h1_tag,Type欄選擇節點類型,Text節點是用來擷取標籤的文字內容。

3.在Web Scraper內建CSS選擇器工具可以從網頁選取文字內容後,自動取得資料的CSS字串,按Select按鈕,可移動游標選取欲選取的目標資料。
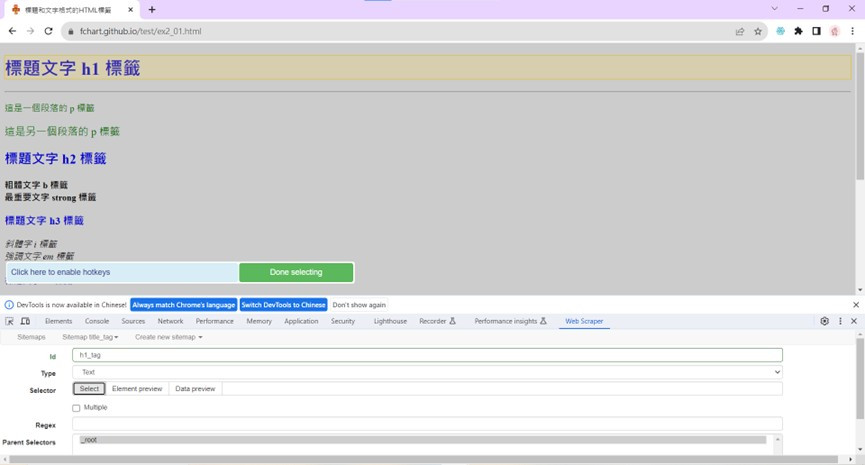
4.當游標移至目標資料後,按滑鼠左鍵,表示選取此元素,同時在下方浮動工具列的前方欄未顯示取得的CSS選擇器h1,如下圖:
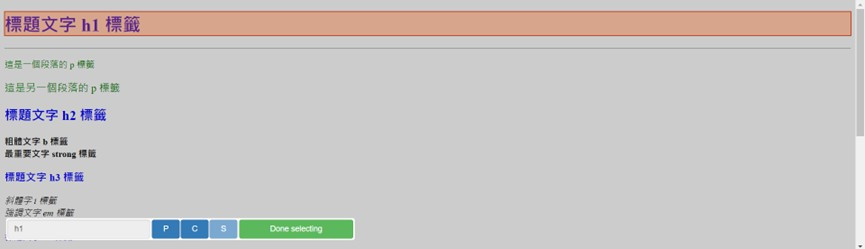
5.選擇完成後,點選Done Selecting完成選擇。可在下方欄位填入選擇元素所取得的CSS選擇器字串,點選Element preview預覽選擇元素,如下圖:

6.點選Data preview可以預覽CSS選擇器擷取的資料,上方是節點名稱,下方是標籤內容。

7.按Save selector儲存選擇器節點,可以在_root跟節點下新增名為h1_tag的選擇器節點。

重複按Add new selector依序新增h2_tag和h3_tag兩個CSS選擇器節點,建立完成後,可以在_root下看到三個Text節點的CSS選擇器,如下圖:

今天的分享就先到這邊啦~後續的部份我們明天再繼續說,明天見!
參考書籍資料:文科生也可以輕鬆學習網路爬蟲
資料爬取練習來源同書籍

